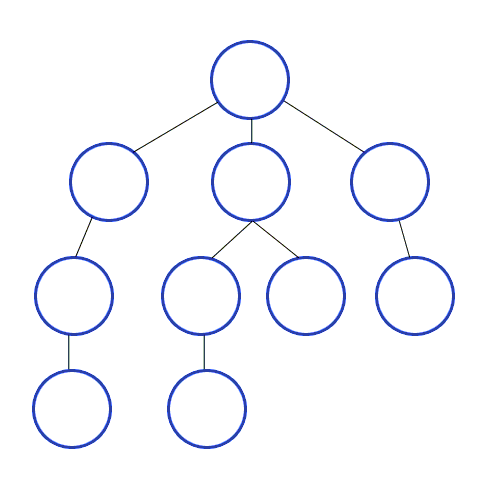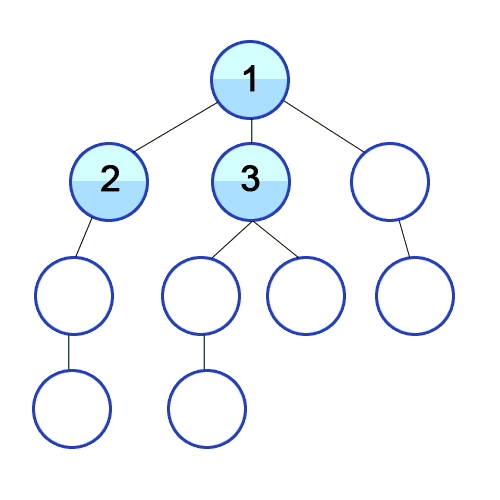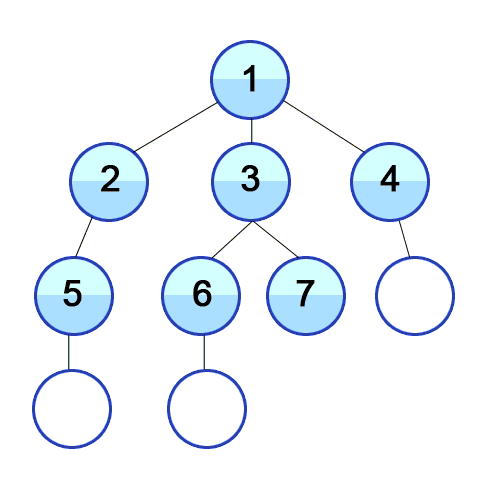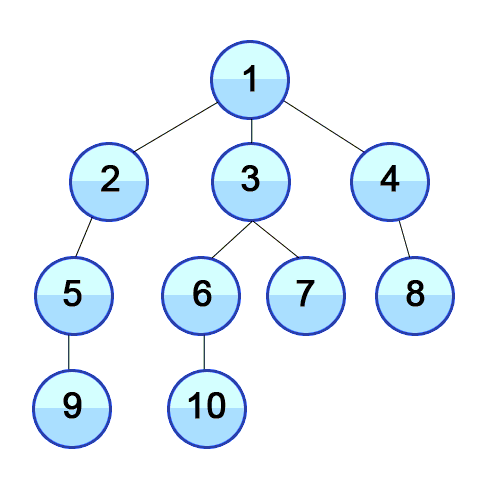
 Breadth first search (
Breadth first search (BFS) - поиск в ширину
Стандартная реализация BFS относит каждую вершину графа к одной из двух категорий:
1. Посещенные
2. Не посещенные
Цель алгоритма - пометить каждую вершину как посещенную, избегая при этом циклов.
Алгоритм работает следующим образом:
- Начните с того, что поместите любую из вершин графа в конец очереди.
- Возьмите первый элемент очереди и добавьте его в список посещенных.
- Создайте список смежных вершин этой вершины. Добавьте в конец очереди те из них, которых нет в списке посещенных.
- Повторяйте шаги 2 и 3, пока очередь не станет пустой.
Граф может иметь две разные несвязные части, поэтому, чтобы убедиться, что мы покрываем каждую вершину, мы можем также запустить алгоритм BFS на каждой вершине.
Для написания простейшего BFS необходимо уметь работать с такой структурой данных, которая позволяет брать из начала и класть в конец (очередь), а также уметь хранить граф в виде списка.
Алгоритм работы на псевдокоде
BFS(G, start):
// Инициализация очереди и множества посещенных вершин
создать пустую очередь Q
добавить start в Q
создать массив посещенных вершин visited (visited[i] = True, если посетили вершину i, иначе False)
добавить start в visited
// Пока очередь не пуста
пока Q не пуста:
Извлекаем вершину из очереди - она будет текущей
Удаляем текущую_вершину из очереди
// Для каждой смежной вершины, которая не была посещена
для каждой смежной_вершины от текущей вершины:
если смежная_вершина не содержится в visited:
добавить смежную_вершину в Q
отметить смежную_вершину в visited
В качестве посещенных вершин можно брать не массив, а множество.
Сложность работы
Так как в худшем случае алгоритм посещает все узлы графа, при хранении графа в виде списков смежности, временная сложность алгоритма составляет O(|V| + |E|), где V - множество вершин графа, а E - множество ребер. Другими словами, алгоритм в худшем случае работает за количество ребер + количество вершин.
Алгоритм поиска в ширину (
BFS) является одним из фундаментальных алгоритмов обхода графа и находит широкое применение во многих областях:
- Поиск кратчайшего пути между двумя вершинами в невзвешенном графе. Это может быть использовано, например, для поиска кратчайшего пути в лабиринте или для определения минимального количества ходов, необходимых для достижения цели.
- Поиск в ширину:
BFS используется для обхода графа в ширину, что означает, что он посещает все вершины на одной уровне перед переходом к следующему уровню. Это может быть полезно, например, при поиске всех соседей вершины или при проверке связности графа.
- Поиск в графе:
BFS может использоваться для поиска конкретной вершины или проверки ее наличия в графе. Он также может быть применен для поиска всех возможных путей от стартовой вершины до целевой вершины.
- Поиск компонент связности:
BFS позволяет найти все вершины, достижимые из данной стартовой вершины, и таким образом определить компоненты связности в графе.
- Поиск взвешенных кратчайших путей: Хотя
BFS обычно используется для невзвешенных графов, он может быть модифицирован для поиска кратчайших путей во взвешенных графах с неотрицательными весами ребер (например, использованием алгоритма Dijkstra).